LeanCTX 开源项目解析:给 AI Agent 加一层本地上下文管理器
摘要
LeanCTX 是一个 Rust 编写的本地上下文智能层,定位在 AI Agent、代码仓库和命令行之间。它试图用压缩、路由、记忆和验证机制,降低长任务中的上下文浪费与工具输出噪音。
LeanCTX 是一个面向 AI Agent 的本地上下文智能层。项目用 Rust 编写,定位在 AI 编程工具、代码仓库、shell 输出和本地数据之间,目标是控制 Agent 能看到什么、记住什么、触碰什么,并记录上下文节省情况。
截至本次整理,yvgude/lean-ctx 在 GitHub 上约有 2746 个 star、278 个 fork,采用 Apache-2.0 License,主语言为 Rust,仓库创建于 2026 年 3 月 23 日,最近一次 push 时间为 2026 年 6 月 17 日。它支持 Cursor、Claude Code、Copilot、Windsurf、Codex、Gemini 等工具,README 中称可覆盖 30 多个 Agent,并提供 76 个 MCP 工具。
LeanCTX GitHub 项目图。图片来源:GitHub
它解决的是 Agent 长任务里的上下文浪费
AI 编程工具在真实项目中经常遇到一个问题:同一个文件被反复读取,git status、npm、cargo、docker、kubectl 等命令输出又长又杂,模型上下文被大量低价值文本占满。上下文窗口变大并不能完全解决这个问题,因为长任务真正需要的是“保留有效信号,压缩重复噪音”。
LeanCTX 的思路是把 context 当成需要管理的资源。它不是直接替代 Cursor 或 Codex,而是在 Agent 和本地环境之间加一层本地二进制工具。Agent 读文件、跑命令、搜索代码、恢复会话时,可以通过 LeanCTX 获取被压缩、路由和记录后的上下文。
README 中给出的典型对比包括:重复文件读取从约 2000 tokens 降到缓存重读约 13 tokens;原始 git status 约 800 tokens,压缩后约 120 tokens。这些数字属于项目方 benchmark 和说明,实际收益会受项目规模、语言、工具调用方式和 Agent 行为影响。
四个核心维度:压缩、路由、记忆、验证
LeanCTX 把能力分成四个维度。
第一是 Compression。它提供 full、map、signatures、diff、lines:N-M、density:X 等 10 种读取模式,可以先给模型结构化摘要,再按需展开具体行段。shell 输出侧,它内置 95 个以上输出压缩模式,覆盖 git、npm、cargo、docker、kubectl、terraform 等常见命令。
第二是 Routing。并不是所有文件都值得完整读入上下文。LeanCTX 会根据文件类型、历史会话和查询复杂度选择合适的读取模式。例如简单定位函数时用 signatures,排查具体 bug 时再展开 line range。
第三是 Memory。它提供 session memory、知识图谱和属性图,让上下文不必在每次聊天或压缩后完全重建。对多轮开发任务来说,能记住已确认事实、任务状态、文件关系和历史决策,往往比单纯扩大上下文窗口更有效。
第四是 Verification。LeanCTX 提供 Context Manager 仪表盘、预算策略和 ctx_proof、ctx_verify 等验证能力,帮助用户看到上下文预算消耗、压缩统计和保存证明。它还强调 savings ledger 是本地记录,并使用 SHA-256 链做防篡改证明。
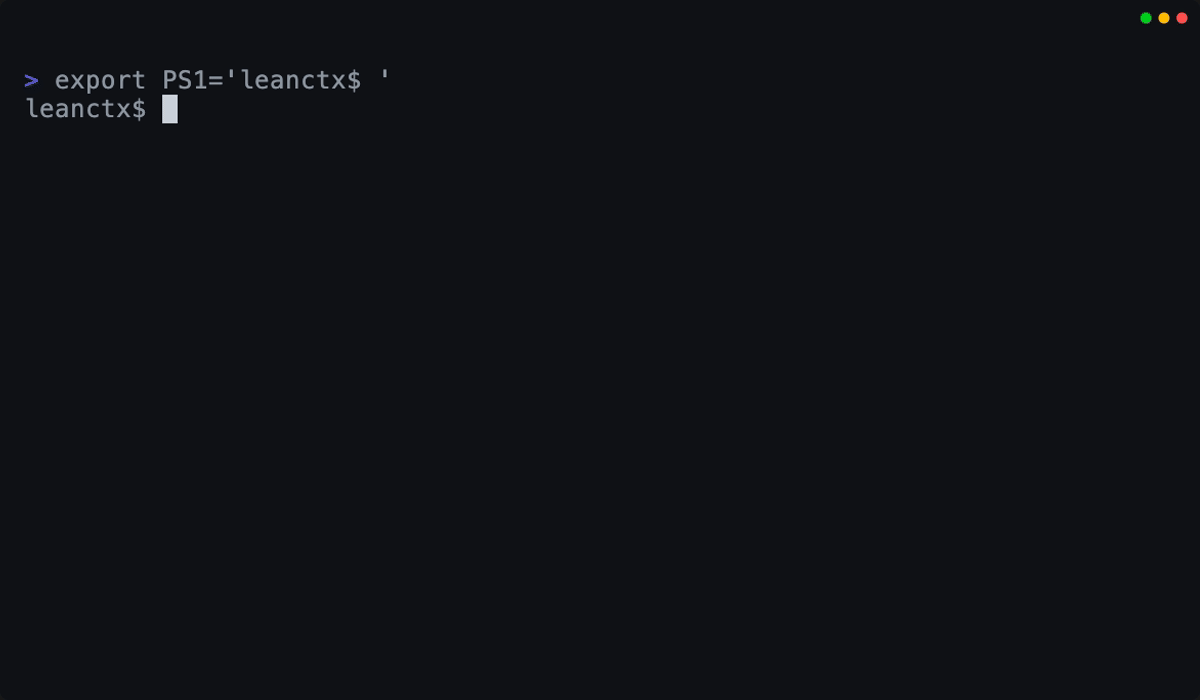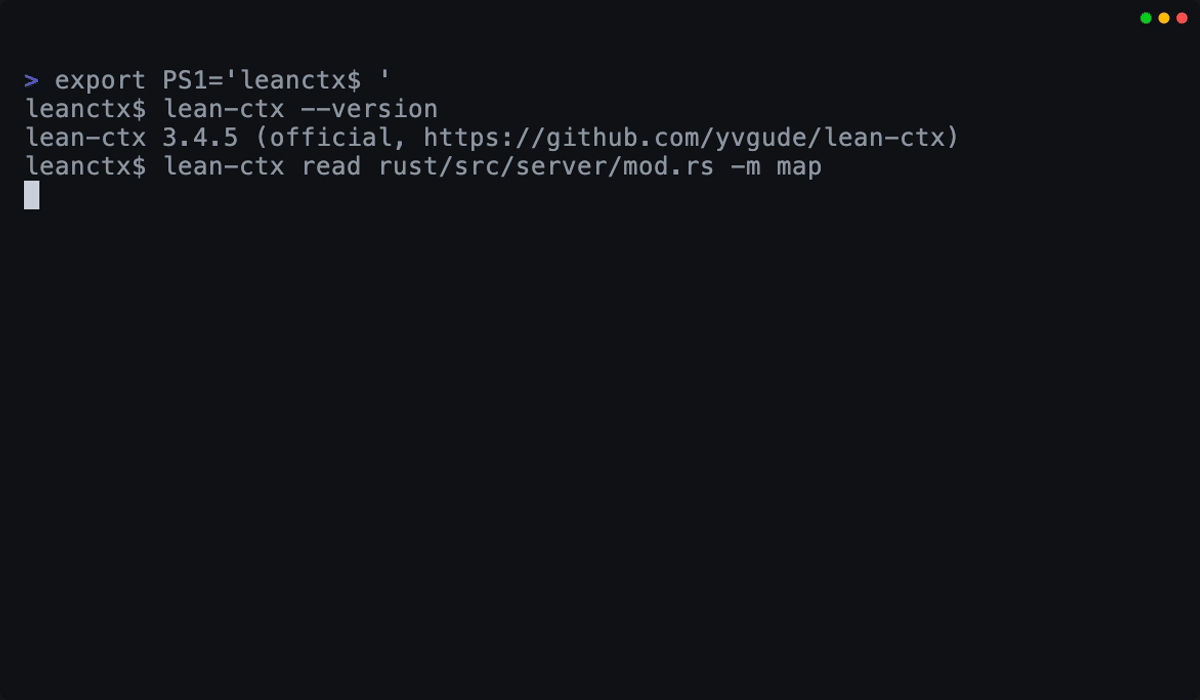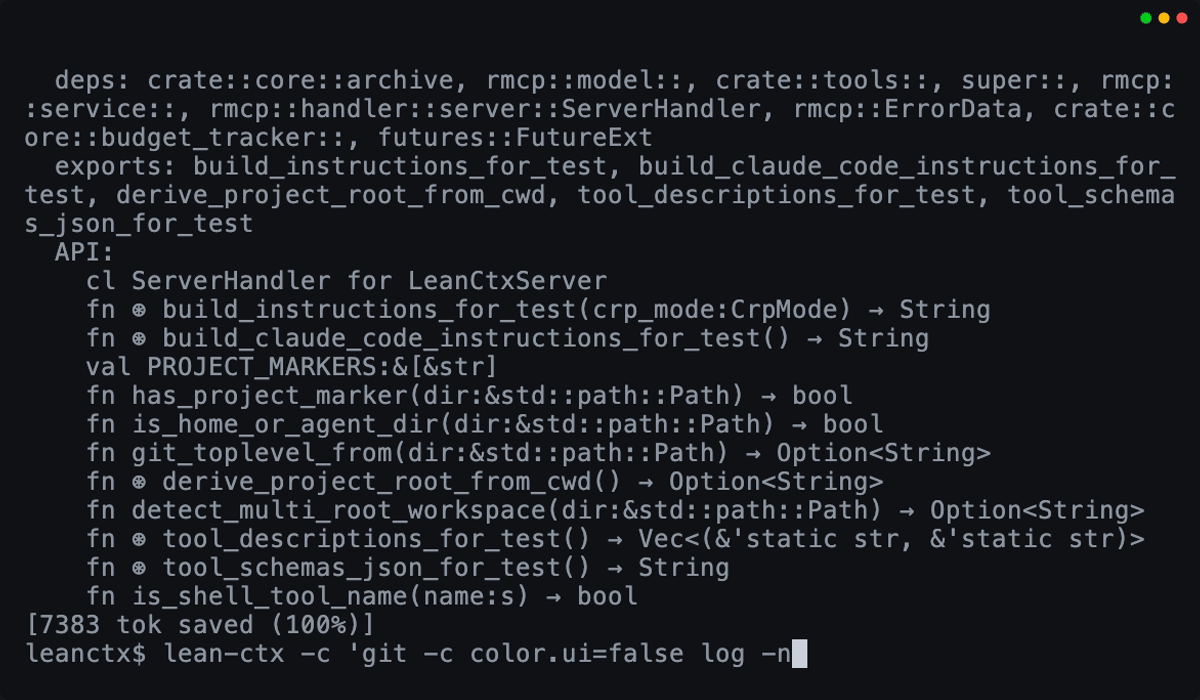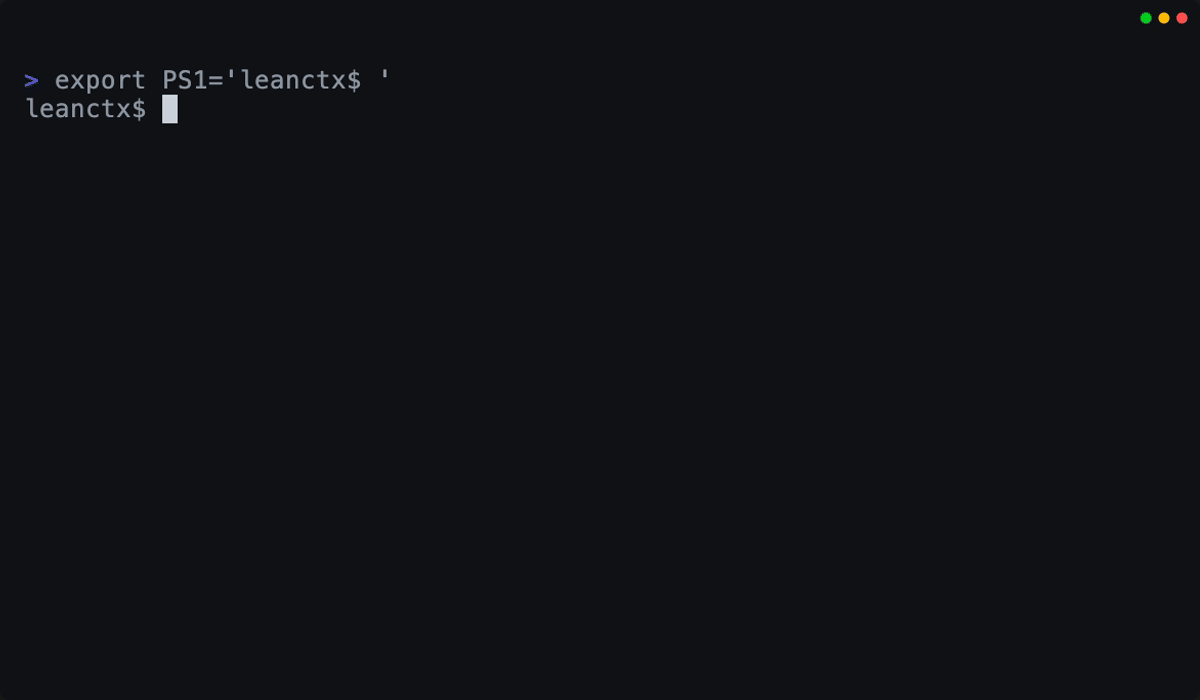
LeanCTX read and shell compression demo。图片来源:LeanCTX GitHub README
MCP 是项目落地的关键接口
LeanCTX 的架构可以概括为:AI tool 通过 MCP tools 和 shell commands 进入 lean-ctx,再由 lean-ctx 访问本地仓库和 CLI。它暴露 ctx_* 工具,覆盖读取模式、缓存、增量、搜索、记忆和多 Agent 协作。
这个方向符合当前 Agent 工具链的发展趋势。MCP 已经成为很多 AI 客户端连接外部工具的事实接口之一,但 MCP Server 越多,工具输出、权限边界和上下文治理就越复杂。LeanCTX 的价值在于,它不只是提供“更多工具”,而是试图给工具调用加一层上下文治理。
项目还提到支持 web research、graph-powered intelligence、LSP refactoring、多 Agent handoff、archive full-text search、PR context packs、context packages、observability 和 HTTP mode 等能力。这个范围很大,也意味着用户在生产环境采用前需要判断哪些能力已经稳定,哪些仍处于快速迭代状态。
安装和接入路径
LeanCTX 提供多种安装方式,包括通用安装脚本、Homebrew、npm、cargo 和 Pi Coding Agent。典型流程是安装后运行 lean-ctx onboard 或 lean-ctx setup,再用 lean-ctx doctor 检查状态。完成 onboarding 后,需要重启 shell 和编辑器或 AI 工具,使 MCP 和 shell hook 生效。
这种接入方式比改造每个 Agent 客户端更现实。对团队来说,关键是先在小项目里观察输出质量:压缩后是否丢失重要上下文,shell hook 是否影响常规命令,session memory 是否能稳定恢复任务状态,仪表盘数据是否足够解释成本变化。
风险和适用边界
LeanCTX 的方向很有价值,但它也处在一个需要验证的领域。上下文压缩如果过度,可能导致模型错过边界条件、注释约束或隐蔽依赖;会话记忆如果没有清晰的过期和来源管理,可能把旧结论带到新任务;工具路由如果判断错误,可能让 Agent 在错误抽象层上做决策。
因此它更适合有明确工程流程的开发者和团队试用:先接入非关键仓库,观察 token 节省、失败案例和 Agent 输出质量,再决定是否放进日常开发链路。对只做轻量问答的用户来说,它可能显得过重;对长时间使用 Codex、Claude Code、Cursor 跑大型仓库任务的用户,价值会更明显。
接下来要看什么
AI 编程从“单次补全”走向“多小时 Agent 任务”后,上下文工程会成为基础设施问题。LeanCTX 代表的不是单个压缩工具,而是一类新层:它管理 Agent 的输入、记忆、工具输出和可验证成本。未来这类项目能否站稳,取决于三点:压缩后的准确性、跨 Agent 兼容性,以及团队能否审计它到底让模型看见了什么。
同类栏目导航