谷歌把屏幕控制能力原生集成进 Gemini 3.5 Flash,企业级智能体离真实办公更近一步
摘要
谷歌将原本独立提供的 Computer Use 能力集成进 Gemini 3.5 Flash,使开发者可以用同一个主力 Flash 模型构建能看屏幕、理解界面并执行点击、输入、滚动等操作的智能体。它面向浏览器、移动端和桌面环境开放,但仍处于预览能力范畴,安全边界和人工确认机制会决定其企业落地速度。
谷歌在6月24日宣布,Computer Use已成为 Gemini 3.5 Flash的内置工具。简单说,开发者现在可以让 Gemini 3.5 Flash看见屏幕、理解界面内容,并生成点击、输入、滚动等操作指令,而不必再单独调用此前的 Gemini 2.5 computer use专用模型。这不是一次普通的 API小更新,它代表谷歌正在把“能聊天的模型”进一步推向“能操作软件的智能体”。
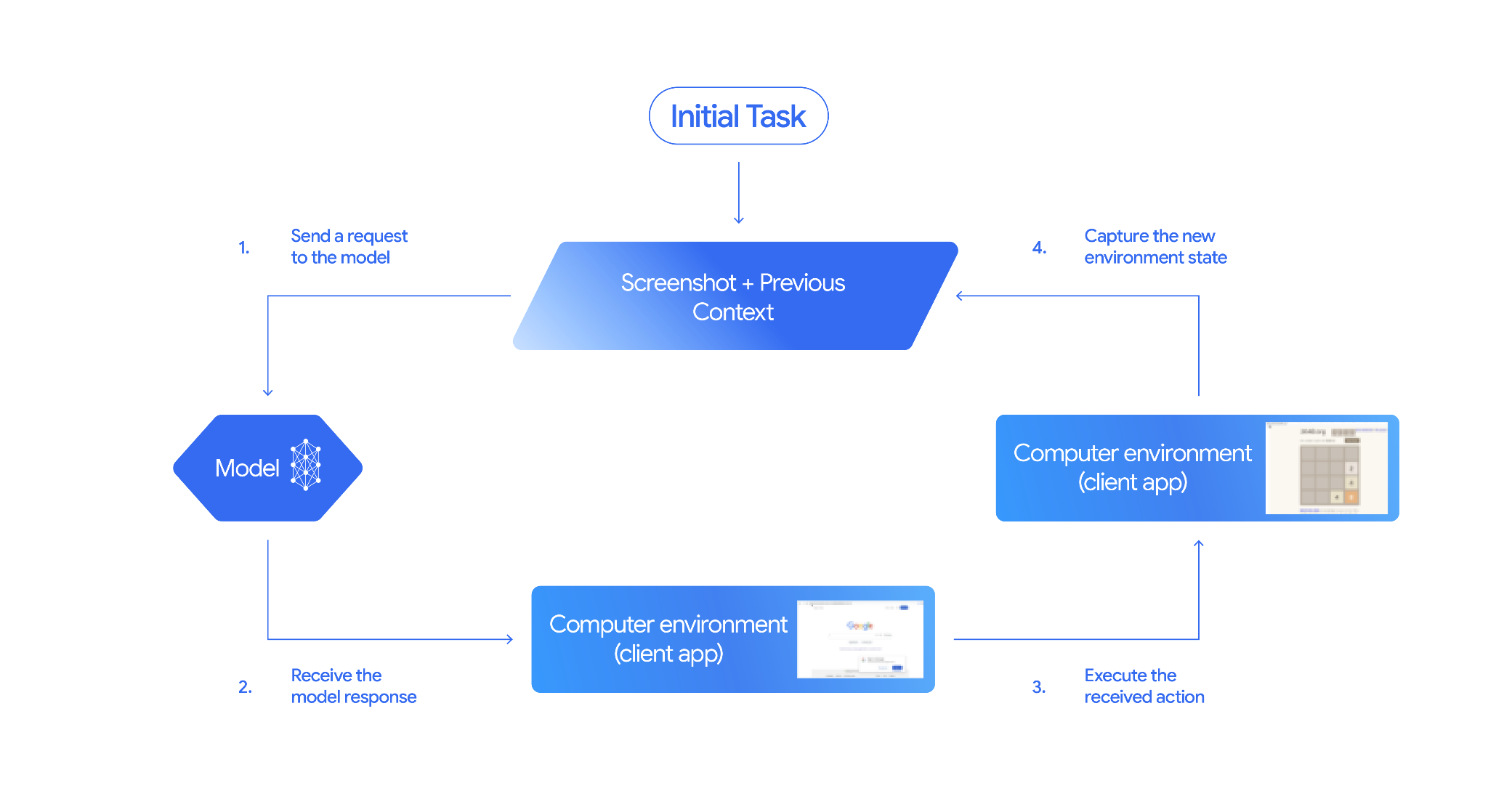
Computer Use 的截图、模型响应、客户端执行与状态回传循环。来源:Google AI for Developers 文档
从专用模型变成 Flash的原生工具
Computer Use可以理解为一种“让模型使用图形界面”的能力。它不是让 AI直接拥有电脑控制权,而是让模型根据截图判断下一步应做什么,再由开发者的客户端程序执行具体动作。准确地说,应用会把当前屏幕截图、用户任务和工具配置发给模型,模型返回结构化的 UI动作,例如点击某个坐标、输入一段文字或滚动页面;客户端执行动作后,再截取新的屏幕状态发回模型,如此循环直到任务完成或被中止。
在这次更新前,谷歌提供的是独立的 Gemini 2.5 computer use preview模型,主要面向浏览器自动化场景。现在,Computer Use被整合进 Gemini 3.5 Flash,开发者可通过 Gemini API或 Gemini Enterprise Agent Platform调用。这意味着同一个 Flash模型可以同时承担理解任务、推理步骤、调用工具、执行代码、联网检索和图形界面交互等职责,减少多个模型之间切换和编排的复杂度。
这对开发者的直接影响是,智能体架构更容易被收敛到一个模型入口。过去,如果一个企业想做“读取网页信息、判断业务规则、填写内部系统表单、再生成报告”的流程,可能需要把文本推理模型、浏览器控制模型和函数调用逻辑拼在一起。现在,Gemini 3.5 Flash至少在模型侧把这些能力放进了同一套工具体系中,工程重点会更多转向执行环境、安全策略、权限隔离和日志审计。
它能做什么:看屏幕、推理、生成操作意图
谷歌官方文档显示,Gemini 3.5 Flash是当前 Computer Use的推荐模型,支持浏览器、移动端和桌面环境。它可以用于重复性数据录入、网站表单填写、Web应用自动化测试,以及跨网页收集产品信息、价格和评论等研究任务。与传统脚本自动化相比,这类能力的特点在于不完全依赖固定的 DOM结构或预写规则,而是通过截图理解界面状态,再决定下一步动作。
一个关键变化是,Gemini 3.5 Flash的 Computer Use响应中会包含 intent字段,也就是模型对当前动作意图的解释。例如,模型不仅返回“点击某处”,还会说明它为什么要点击这里,比如“点击搜索框以输入目的地”。这个设计对企业调试和审计很重要,因为智能体失败时,工程团队需要知道它是看错了界面、误解了任务,还是执行环境出了问题。
不过,Computer Use并不等于模型可以绕过开发者控制直接操作电脑。谷歌文档明确要求开发者实现客户端执行环境,用来接收模型返回的动作、换算坐标、执行点击或输入,并在下一步继续截屏回传。换句话说,模型负责“判断和发出建议动作”,真正执行动作的是开发者控制的自动化层,常见实现会使用 Playwright这样的浏览器自动化工具,生产环境则需要放进沙箱、虚拟机或容器中运行。

图片来源:blog.google
为什么企业场景会关心这项能力
企业自动化过去有两类常见方案:一类是传统 RPA,通过录制步骤、识别按钮和固定规则操作软件;另一类是 API集成,通过系统之间的正式接口交换数据。前者对界面变化敏感,后者依赖软件是否开放接口。Computer Use的价值在于补上中间地带:当一个流程涉及多个网页、内部工具、旧系统和临时界面时,AI智能体可以像人一样“看着屏幕走流程”。
谷歌在公告中提到的典型方向包括持续软件测试和专业应用中的知识工作。持续软件测试很好理解:一个测试智能体可以打开应用、执行用户路径、检查页面是否出现预期内容,并把失败步骤记录下来。知识工作则更宽泛,可能包括在后台系统检索资料、填报表单、整理仪表盘信息,或者根据多个业务页面完成跨系统任务。
这类能力的吸引力不只在“省人力”,更在于降低自动化门槛。很多企业并不是没有流程,而是流程分散在多个 SaaS、网页后台、Excel、内部系统和邮件里。传统自动化要么改造成本高,要么容易被界面变化打断。基于 Computer Use的智能体仍然会出错,但它给了企业另一种选择:先在沙箱和低风险任务里试运行,再逐步把稳定路径沉淀成规则或正式接口。
安全设计是这次更新的重点
让模型能操作屏幕,也会放大安全风险。最大的问题之一是提示词注入。用人话说,就是网页、文档或截图里藏着一段恶意指令,试图诱导智能体忽略原本任务,转而泄露信息、点击危险按钮或执行非预期操作。对普通聊天机器人来说,这可能只是回答偏题;对能点击和输入的智能体来说,它可能变成真实操作风险。
谷歌称,Gemini 3.5 Flash的 Computer Use针对这类场景进行了对抗训练,并提供两项可选的企业级防护:一是对敏感或不可逆操作要求用户明确确认,例如支付、提交关键表单、删除数据、修改敏感记录;二是在检测到间接提示词注入时自动停止任务。官方文档还提到,Gemini 3.5 Flash支持可配置安全策略,覆盖金融交易、敏感数据修改、通讯工具、账号创建、数据修改、同意管理和法律条款等类别。
这些机制的意义在于把“智能体自主性”拆成可治理的层级。企业未必会接受一个 AI自动完成所有点击,但可能接受它先走到关键步骤,然后让人确认;也未必会让它访问生产数据库,但可以让它在隔离浏览器中完成测试账号流程。真正能落地的 Computer Use,不会是没有边界的全自动控制,而是模型推理、沙箱执行、权限限制、人工确认和日志追踪组合起来的系统工程。
仍然是预览能力,不能当成可靠员工
需要强调的是,谷歌文档仍将 Computer Use标注为预览能力,并提示它可能包含错误和安全漏洞。官方建议开发者在重要任务中保持监督,避免将其用于涉及关键决策、敏感数据或一旦出错难以纠正的操作。这一点很关键:能看屏幕和能可靠完成企业流程之间,仍然隔着稳定性、权限、异常处理、合规和责任归属。
从技术角度看,基于截图的智能体天然会遇到几个限制。第一,视觉理解可能出错,特别是界面元素拥挤、弹窗遮挡、语言混杂或屏幕分辨率变化时。第二,坐标动作需要与客户端环境精确匹配,否则点击位置可能偏移。第三,长周期任务中,页面加载、登录态过期、验证码、网络失败和权限不足都会打断流程。第四,安全策略过严会降低自动化效率,策略过松又会增加误操作风险。
因此,企业采用这类能力时,最现实的路线不是立刻替代员工,而是从低风险、高重复、可回滚的任务开始。比如测试环境中的 UI回归测试、公开网页信息汇总、内部知识库导航、表单草稿生成、非关键系统的数据核对。等到日志、评估集、失败回放和人工确认流程成熟后,再考虑把它接入更高价值的业务路径。
在谷歌 AI战略中的位置
Gemini 3.5 Flash是谷歌在 I/O 2026发布的 Flash系列模型,定位是速度、成本和智能体能力之间的平衡点。它已进入 Gemini API、Google AI Studio、Android Studio、Gemini Enterprise相关平台,并被谷歌用于 Gemini应用和 Search的 AI Mode。把 Computer Use原生接入 Flash,等于让这条主力模型线覆盖更多“行动型 AI”场景。
这也反映出大模型竞争的一个变化:模型厂商不再只比文本回答质量,而是在比谁能更安全、更稳定地连接真实工具。函数调用解决的是 API世界的问题,代码执行解决的是计算和脚本问题,搜索增强解决的是信息获取问题,而 Computer Use解决的是大量没有好接口、仍然依赖图形界面的软件世界。
对开发者来说,接下来最值得观察的是三件事:Gemini 3.5 Flash在真实长流程任务中的成功率是否足够稳定;企业安全策略是否能在不牺牲太多效率的前提下降低风险;以及 Computer Use能否与现有 RPA、测试框架、浏览器自动化和企业权限系统顺畅结合。谷歌这次更新让屏幕智能体更接近主流开发入口,但它距离“放心交给 AI操作公司系统”仍需要更多验证。
同类栏目导航